从漏洞挖掘到风险治理:AI 闭环下的代码安全范式变迁与从业者转型
2026年2月20日,Anthropic正式发布Claude Code Security,旨在全自动扫描代码库并直接在开发者的工作流中提供修复建议。这一事件在短短48小时内蒸发了全球网络安全资本市场约150亿美元的市值,CrowdStrike、Palo Alto Networks等传统巨头股价重挫。市场的剧烈反应折射出一种普遍恐慌:当AI在生成、检测、修复代码的链条上完成逻辑闭环时,传统安全防御体系及从业者的价值在哪里?
这种恐慌,本质上源于对AI能力边界的模糊认知,以及对软件安全本质的误解。剥开产品外衣,AI并未解决所有安全难题,但它确实标记了行业的拐点——安全的智能化转型,从企业的视角来看,真正的挑战已从单纯的“挖掘漏洞”转移到了架构韧性、自动化验证以及复杂逻辑的持续治理,核心目标是控制风险。
随着现代软件开发流程已逐渐AI化,各大企业也要求员工使用AI进行提效,作为一个安全从业者,我观察到漏洞挖掘的范式已经发生巨变:从早期依赖人工与静态工具,经由深度学习的“伪泛化”阶段,最终跨越至当下由Agentic主导的自主审计时代。本文将从技术演进与企业真实视角的双重维度,拆解这一自动化漏洞挖掘的范式变迁,并探讨在这场智能化浪潮中,安全工程师的破局之道。
前LLM时代:规则驱动与特征拟合
在大模型取得突破前,漏洞挖掘受限于确定性程序的刚性规则,以及早期机器学习在语义理解上的先天不足。这一阶段虽奠定了自动化基础,但也彻底暴露了“程序分析”与“特征拟合”的根本缺陷。
静态分析:规则驱动和断流问题
早期的自动化漏洞挖掘高度依赖于静态应用程序安全测试(SAST)工具,如CodeQL、Tabby等。这类工具的核心逻辑是通过词法分析与语法分析,将源代码标准化为抽象语法树(AST),进而构建控制流图(CFG)与数据依赖图(DDG),最终通过污点分析(Taint Analysis)来追踪不可信的外部输入(Source)是否能够未经验证地到达敏感的执行节点(Sink) 。
但这种模式存在两大难以逾越的障碍:
- 无止尽的规则维护: 覆盖率极度依赖人工定义规则,对抗新型漏洞疲于奔命。
- 动态特性的“断流”: 尽管应对显式语法漏洞(如SQLi、XSS)卓有成效,但在现代高级语言面前极其脆弱。以Java语言为例,其广泛使用的反射机制、动态代理等特性,会在静态分析过程中导致调用图的极度碎片化 。当程序在运行时通过反射动态决定调用哪一个类或方法时,基于静态源码的分析器无法预知确切的执行路径。即使引入类层次结构分析(CHA)等辅助手段,静态分析也必须采取极其保守的策略,穷举所有潜在的执行路径,这不可避免地导致了路径爆炸与海量的误报 。
此外,SAST本质是在“寻找已知的不安全模式”,因此对因逻辑缺失导致的“逻辑漏洞”(如越权访问)几乎完全免疫。前LLM时代的静态分析,本质上是在用人工规则的确定性换取覆盖率,代价是面对复杂业务时必然的断流、误报与逻辑盲区。
深度学习:过拟合与泛化问题
为打破规则枷锁,学术界曾寄希望于深度学习(如VulDeePecker, LineVul等),试图将代码转化为向量,把漏洞检测降维成序列或图节点分类问题,以期模型能自动捕捉漏洞的根本原因。
- VulDeePecker: A Deep Learning-Based System for Vulnerability Detection
- LineVul: A Transformer-based Line-Level Vulnerability Prediction
- VulChecker: Graph-based Vulnerability Localization in Source Code
然而,这些基于Transformer或图神经网络的深度学习模型在实际应用中并不work。根本原因在于:早期深度学习模型本质上是在高维空间拟合训练数据的“统计学特征”,而非进行真正的“语义推理”。
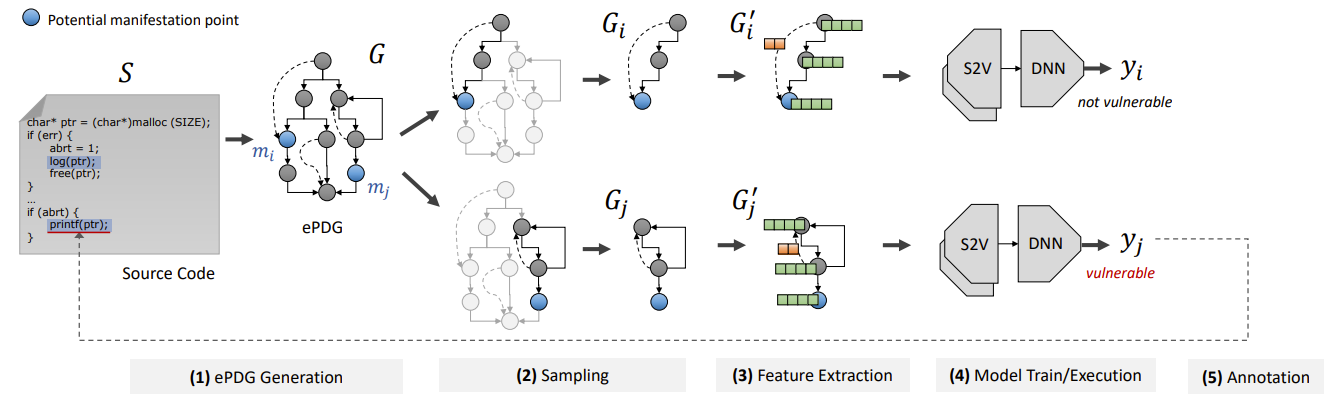
漏洞是高度上下文相关的。早期模型多基于切片或函数的局部视图训练,导致它们学到的往往是训练集中特定的“变量命名习惯”或“代码格式”,而非漏洞本身的控制流逻辑。这种特征拟合带来了两个致命后果:
- 较低的泛化能力: 一旦部署到包含不完整切片、复杂宏定义及混合语言的企业级代码库中,准确率便断崖式下跌。
- 容易受对抗攻击: 因为缺乏对Root Cause的理解,攻击者只需插入无意义的死代码(Dead Code)或更改变量名,就能轻易欺骗模型,将恶意代码判断为安全。
这意味着,传统深度学习路线解决的仅仅是“相似分布上的特征识别”,而非“真实工程语境下的逻辑推理”。 面对企业级代码的噪声与复杂上下文,它根本无法胜任主力审计工具。
LLM时代:语义驱动
随着大语言模型(LLM)的崛起,漏洞挖掘范式迎来了实质性的跨越。这一演进并非一蹴而就,而是经历了一个从“LLM与传统分析工具双向互辅”到“智能体(Agentic)自主闭环”的渐进变迁。
拥有更长上下文窗口、更强语义推理能力且幻觉率持续降低的 LLM,让原先静态分析中的死局逐渐有了破局之法。LLM 带来的核心质变绝不仅是“更会猜”,而是首次让模型具备了跨上下文的语义理解能力,使得过去静态工具难以建模的代码逻辑与开发者意图,真正变得可推演、可操作。
LLM与静态分析的双向结合
在这一阶段,受限于早期模型较小的上下文窗口和固有的幻觉问题,业界对 AI for Security 的探索主要沿着两条双向辅助的路径展开:
范式1: LLM 辅助传统工具
顾名思义,传统工具依旧占据主导位置,此时人们利用LLM来解决传统的静态分析当中存在的局限性,例如规则的编写费时费力,针对业务逻辑漏洞无法进行建模等。
以 IRIS 项目为例。传统静态分析(如 CodeQL)极度依赖人工定义复杂的污点源(Source)和汇聚点(Sink)。IRIS 提出了一种神经符号(Neuro-symbolic)方法,利用 LLM 的语义理解力自动推断代码库的污点规范,并将其转化为可执行的 CodeQL 查询。更进一步,针对 CodeQL 产生的海量误报,IRIS 提取静态报告的执行路径及上下文,构建结构化 Prompt 交由 LLM 进行二次推理过滤。这套组合拳在真实 Java 项目中,不仅找出了 CodeQL 无法独立发现的漏洞,更大幅压降了错误发现率。
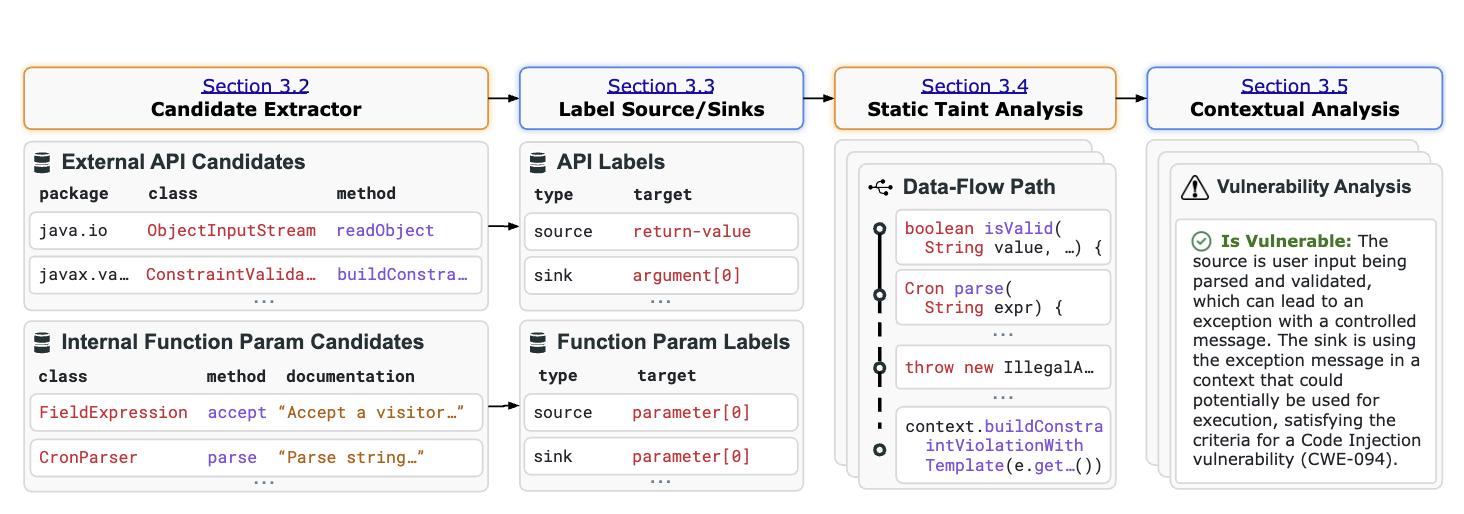
- IRIS: LLM-Assisted Static Analysis for Detecting Security Vulnerabilities
另一个典型案例是 GPTScan。智能合约中的逻辑漏洞(如价格操纵、越权)往往没有语法错误,根本原因隐藏在业务规则冲突中。GPTScan 将高度抽象的漏洞拆解为具体的“场景(Scenarios)”和“属性(Properties)”,引导大模型进行精准的语义匹配。为消除幻觉,系统随后会调用底层的数据流追踪和符号执行引擎进行严谨的交叉验证。

- GPTScan: Detecting Logic Vulnerabilities in Smart Contracts by Combining GPT with Program Analysis
这一范式的本质是:用LLM降低“规则与语义建模”的人力成本,同时把最终裁决交给可重复的确定性分析来兜住幻觉风险。
范式2: 传统工具辅助LLM
面对数十万行的真实代码库,直接“喂”给早期 LLM 并不现实。这一路线的核心在于:如何为 LLM 准备最精准的上下文。
研究项目如 LLMxCPG 巧妙地利用 Joern 等基础静态工具,预先提取代码属性图(CPG),并通过污点分析剥离出潜在漏洞相关的上下文切片。这些经过传统工具“提纯”的结构化数据,被精准地送入大模型进行深度推理。实证表明,这种图结构指导的方法在稀有漏洞类型的检测上,F1 分数远超单纯的深度学习微调模型。

- LLMxCPG: Context-Aware Vulnerability Detection Through Code Property Graph-Guided Large Language Models
这一范式的本质是:用传统分析完成“上下文提纯与结构化”,让LLM把算力花在推理上,而不是浪费在阅读噪声上。
Agentic范式:自主代码审计闭环
2025年至2026年,随着大模型推理能力的跃升,漏洞挖掘正式步入了Agentic(智能体)时代。这一阶段的标志性特征是,LLM不再仅仅被视为一个静态的代码阅读器或辅助工具,而是被赋予了业务知识、专家经验,并能够与环境进行动态交互的自主审计员 。
Agentic 范式的基石由 Google Project Zero 2024年发布的 Project Naptime(后演进为 Big Sleep)奠定。它为大模型配置了代码浏览器、Python沙箱、GDB等完整工具链,让AI首次展现出类似人类研究员的动态行为:**自主假设 → 编写测试 → 调试观察 → 根据反馈迭代利用。**2024年10月,Big Sleep 在 SQLite 中独立发现了一个可利用的 stack buffer underflow 漏洞,标志着漏洞挖掘基准已从静态匹配转向动态、反馈驱动的 agentic 审计。
然而,Big Sleep 证明了单点突破的可行性,但要在动辄数百万行的企业级仓库中落地,挑战依然巨大。在此背景下,RepoAudit作为首个纯LLM驱动的仓库级代码审计多智能体系统应运而生 。为了解决大仓库审计的难题,它设计了三个核心组件及一个记忆中枢来复刻专家思维:
- 启动器(Initiator): 根据漏洞定义和目标仓库作为输入,精准识别需要分析的初始危险数据源头(Source values)。
- 探索者(Explorer): 采用按需驱动(Demand-driven)策略,沿着复杂的函数调用链进行迭代探索,每次向模型下发单一函数的分析指令。
- 智能体记忆(Agent Memory): 位于探索的中枢,每次分析的数据流事实会被结构化地存入记忆中,以指导智能体进一步的探索连贯性。
- 验证器(Validator): 为遏制大模型幻觉,验证器从多个维度严格验证探索者的输出。它摒弃了容易导致路径爆炸的传统 SMT 求解器,转而通过提示 LLM 自主排查跨函数路径条件中的逻辑矛盾,以极低的成本大幅削减了误报率。
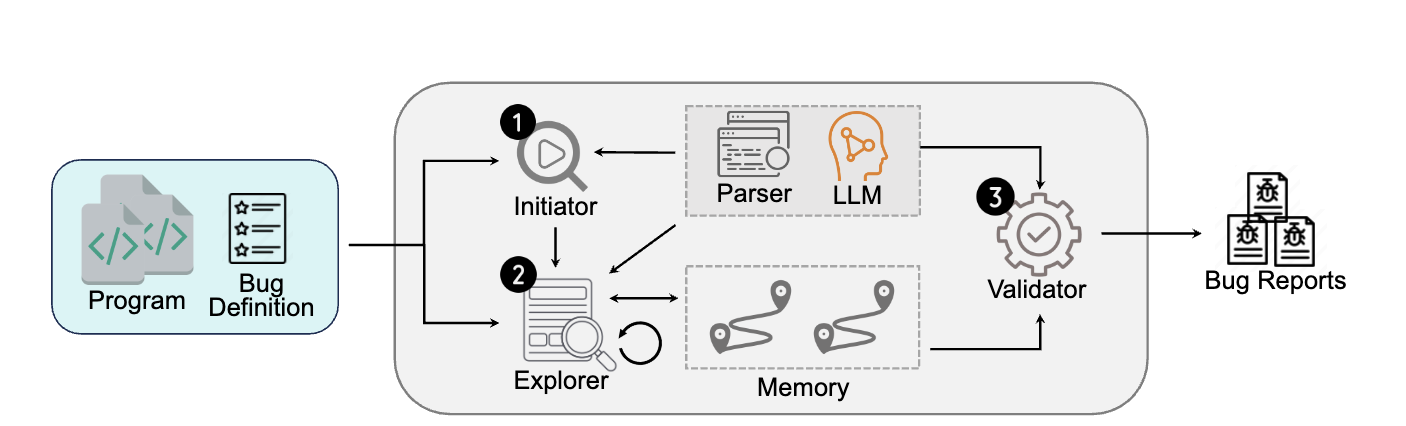
- RepoAudit: Automated Code Auditing with Multi-Agent LLM Framework
沿着这一条道路,2025年工业界的各大厂商也产出了多个实践方案,但是大体上都是直接利用强大的LLM模型进行自主的代码走读和漏洞发现,在这个过程当中设计各种Agent工程来保证漏洞挖掘的准召率,例如:
- 静态分析信息辅助
- 动态的上下文注入
- Plan and Excuete,React等思考模式
- 特定的企业业务知识注入
- 多agent协作验证
Agentic 时代真正的分水岭在于:它不再是让模型进行一次性的判断,让漏洞挖掘演变为“假设—验证—反馈—修正”的循环。在这一刻,AI 的工作方式,真正开始与人类安全专家同频共振。
真知灼见:漏洞挖掘的哲学
从整个漏洞挖掘范式的变迁中不难看出,所有方法的演进,本质上都是在平衡准确率(Precision/减少误报)与覆盖率(Recall/减少漏报)。这个核心矛盾并非工程能力不足,而是源于一个计算机科学的理论局限——莱斯定理(Rice's Theorem)。
数学家 Henry Rice 证明:**对于任何图灵完备的编程语言,关于其计算函数的所有非平凡的语义属性,都是不可判定的。**非平凡属性指的是属性不是所有程序都满足,也不是所有程序都不满足。
给定一个程序或程序片段,是否存在漏洞?这是一个非平凡的属性,因为:
- 存在一些程序是安全的(没有漏洞)。
- 存在一些程序是不安全的(有漏洞)。
同时,漏洞是程序行为的一种特定性质,通常涉及程序执行过程中的特定条件(如内存泄漏、缓冲区溢出、SQL注入等)。这些性质通常不能仅通过语法分析(即单纯查看代码的文本结构)来确定,而需要理解程序的语义(即程序在运行时如何表现,执行时的状态如何变化)。根据莱斯定理,既然漏洞检测是非平凡的语义属性,那么世界上就不存在一种通用算法,能在所有情况下精准判定任意程序是否存在漏洞。
这就是为什么传统 SAST 工具为了避免漏报,只能被迫采取极度保守的穷举策略,进而引发大量误报。而在 LLM 时代,尽管理解能力发生了质的飞跃,但面对极其复杂的非线性业务逻辑分支,模型依然会受限于状态空间的不可计算性,或产生不可预知的幻觉。因此,即使在最前沿的 Agentic 时代,追求理论上 100% 的准召率依然是不切实际的。
那么在当下这个时代,LLM到底还存在哪些局限性,我们又该在什么方面进行探索?
- 注意力坍缩与全局视角的缺失: 基于 Transformer 架构的模型在面对超长上下文和复杂的企业级代码架构时,难以从全局视角精准追踪数据流与控制流。
- 垂直领域知识的稀缺: 尤其是针对企业内部高度定制化的业务架构,模型必须依赖外部知识(如私有框架、内部鉴权中间件)的注入,才能真正理解“什么是业务功能,什么是安全防护”。
- 记忆与进化能力的迟钝: 现有的 LLM 尚未实现通过实时交互来迭代内化记忆。对于已经排查过的同类漏洞,模型难以形成肌肉记忆来确保“不再犯错”。
- 概率模型的固有不确定性: 幻觉可以被压缩,但无法被消灭。同一个模型在多次审计同一段代码时,可能会输出不一致的结果。
那么在未来较长的一段时间,自动化漏洞挖掘可能还是会从这几个方面进行探索和提升:
- Agent 工程的精细化编排: 如何设计多智能体的协作机制、管理长程上下文,以及构建更具引导性的提示词(Prompt)工程。
- 记忆与进化机制的落地: 依赖模型底层的演进,以及上层 Agent 架构(如基于文件系统的动态记忆池)的设计,让 AI 具备真正能够把之前的审计经验,工具执行轨迹进行累积的能力。
- 领域专家知识的深度注入: 安全专家的稀缺性在于对业务风险的敏锐嗅觉。如何将这种非结构化的“专家经验”转化为指导 Agent 工作的规则与知识库,是传统安全从业者转型的关键所在。
- 构建“AI 友好型”基础设施: 随着 LLM 能力的增强,我们需要从“用 AI 辅助现有工具”转变为“设计更方便 AI 调用的原生工具链”,例如更好的代码搜索能力。
- 审计结果的可验证性: 面对概率模型,必须通过结合静态分析兜底、动态流量重放等确定性手段,确保 AI 的审计结果准确且可回溯。
最终,我们期望达成的愿景是:Agent 能够自主挖掘、持续进化,不断攻克复杂逻辑漏洞。我们不再执着于理论上的 100%,而是通过严密的验证与治理体系,区分出AI能力的边界,从而更好的和人类协同。
企业角度的思考
理论上的不可判定性,注定了技术工具永远无法达到 100% 的完美。而当我们将视线从代码仓库移向真实运转的企业时,这种不完美就变成了企业必须直面的风险管理问题。对于个人来讲,针对一个代码仓库能够挖掘出足够多的漏洞可能就是终点。但是企业的逻辑是不一样的,安全对于企业来说有两层价值:守风险底线 + 成为业务竞争力[1]。
守风险底线,保护业务安全健康发展。无论什么行业,在当前时代都需要依赖计算机、处理敏感数据、管理资金、执行生产工作、提供对外服务等。一旦遭遇网络攻击导致生产中断、数据泄漏、资金损失,轻则损失钱财,重则失去用户信任、受到监管处罚等。
让安全成为业务竞争力。安全不只是负向保障,也能成为正向优势。
- 以支付行业为例,早期的线上交易面临极大的信任鸿沟,担保交易的出现构建了最初的信任底座。随后,为了在金融级安全的极高门槛(U盾、指定浏览器)下提升极其糟糕的用户体验,支付平台利用自身的安全风控优势,首创了基于短信校验的“快捷支付”,并抛出“你敢付,我敢赔”的承诺,瞬间打通了支付成功率的瓶颈。到了余额宝时代,为了让用户安心将银行里的钱转移到线上货币基金,平台再次升级赔付承诺,推出额度远超传统存款保险的“账户安全险”。正是这种极致的安全兜底,造就了爆款金融产品。此后的刷脸支付、扫码支付,无一不是建立在底层风控与安全技术的突破之上,最终实现了安全与便捷的完美统一。
对企业而言,漏洞挖掘从来不是终点。真正的目标是在AI参与代码生成、审计与修复之后,风险仍然可控、结果可追溯、责任可界定。所以在AI时代,我们思考的角度应该更上一个台阶,那就是什么样的安全体系才是有效的紧跟时代发展的。当大家的关注点都在AI提效的时候,作为安全工程师更应该思考AI提效之后,安全风险是否依然得到控制和保障,是否又会引入新的风险。所以这又回到了一个核心问题,以前是依靠人来兜底安全风险,那么当ai闭环了大量安全工作之后,AI的结果是否值得信任,如果不信任,如何区分AI能力的边界并协同安全工程师。
换句话说,AI确实能把大量执行工作自动化,但企业真正要建设的是“可验证的治理闭环”:让每一次发现、每一次修复、每一次放行都有可追溯、可复现、可解释的依据。只有这样,AI闭环才不是把风险从“人”转移到“模型”,而是把风险纳入一个可被管理的工程体系。
用代码安全为例,在传统安全架构当中,代码安全的保障依赖于SDL流程,总体来讲可以分为代码生成,代码审计以及代码修复,当AI闭环这个路径之后,依然存在的问题是什么?
-
代码生成
-
AI生成的代码是否存在漏洞
-
如何减少AI生成漏洞的概率
-
-
代码审计
-
AI发现的漏洞的准召率该如何保障,覆盖的漏洞类型是否足够
-
如何确保代码审计结果的可验证性
-
明确AI的能力边界,当AI结果不可信的时候,人应该如何更好的介入进行兜底
-
-
代码修复
-
AI如何准确的定位漏洞代码并进行符合企业安全架构的修复
-
如何验证修复是否完善,同时不会影响本身的业务功能
-
安全工程师的现在和未来
回顾 2025 年,业界广泛探索了 AI 在安全领域的应用,构建了诸如代码审计 Agent、需求分析 Agent 等智能工具。然而现实是,许多安全工程师并未真正从繁杂的日常中被“解放”出来。原因在于,当前 AI 依然存在固有的能力边界。当 AI 的输出结果不够稳定可信时,安全工程师仍需被迫为其“兜底”,这反而衍生出了新的重复性验证工作。
聚焦代码安全领域,我们可以清晰地看到安全工程师职业发展的一条核心脉络:过去,安全工程师的工作范式更多是“执行者”,负责在开发生命周期的具体环节中亲手排查风险。然而,当“执行”这一动作被自动化与智能化吞噬时,安全工程师的稀缺价值,将从“亲手发现问题”迁移为“定义问题、设计体系、划定边界并为结果负责”。
我认为有几个值得思考的方向:
- 安全专家的壁垒是丰富的专家经验和对风险的判断能力,AI 擅长执行,但不擅长定义问题,安全的定义是主观的,什么是业务功能,什么可能导致安全风险。在未来,每个安全工程师都应当具备架构师的思维,去精准定义风险,并在 AI 全面介入的研发流中,设计出能持续抵御未知威胁的新一代防御体系。
- 如果AI的结果都需要人来兜底,那么提效就是一个伪命题,安全工程师必须持续探测和评估 AI 的能力边界,明确在复杂的业务场景中,哪一层可以放心交给 Agent 闭环,哪一种必须触发人类专家的介入。建立一套人机协同的边界标准与信任机制,才是提效的根本。
- AI本身的安全。随着企业内部部署的 Agent 呈指数级增长,AI 系统自身的脆弱性将成为新的攻击面。从 AI 供应链安全、恶意提示词注入、训练数据污染,到多 Agent 交互与执行过程中的越权失控,如何保障智能化基础设施自身的坚不可摧,将是安全行业永恒的命题。
当然,最实际的还是在这个时代持续学习,不断的打造自身的影响力,保持好奇和专注,这不仅仅是安全行业,也是每个人在这个时代都应该确立的价值锚点。
[1] https://feei.cn/cybersecurity-defense-challenges-and-breakthroughs/